问题
前几天看到某Java交流群有个群友问了个关于HashMap的问题如图:
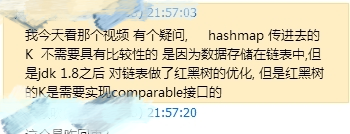
他的疑问就是HashMap1.8当数据结构转为红黑树时,其key为什么不需要比较?
我打赌他肯定没看过HashMap源码,至少看的不深入。
知识补充
首先大家都应该知道HashMap1.8的数据结构吧?以及默认链表长度超过8时会转为红黑树,红黑树大家都知道是啥结构吧?大家也都是有经验的程序员了。
简单介绍下红黑树(Red-Black Tree,简称R-B Tree)吧,它一种特殊的二叉查找树。
红黑树是特殊的二叉查找树,意味着它满足二叉查找树的特征:任意一个节点所包含的键值,大于等于左孩子的键值,小于等于右孩子的键值。
红黑树的每个节点上都有存储位表示节点的颜色,颜色是红(Red)或黑(Black)。
红黑树的特性:
(1) 每个节点或者是黑色,或者是红色。
(2) 根节点是黑色。
(3) 每个叶子节点是黑色。 [注意:这里叶子节点,是指为空的叶子节点!]
(4) 如果一个节点是红色的,则它的子节点必须是黑色的。
(5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
看下红黑树数据结构图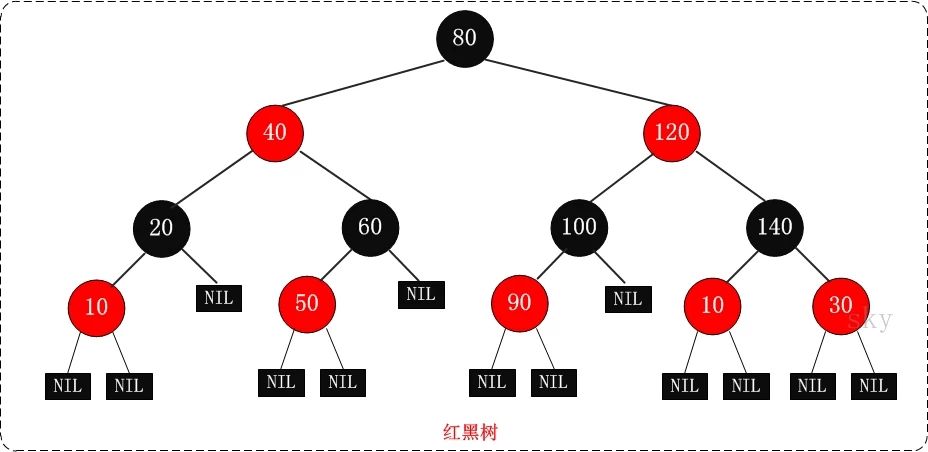
网上随便找了个Java版红黑树实现(部分)
1 | public class RBTree<T extends Comparable<T>> { |
添加操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52/*
* 将结点插入到红黑树中
*
* 参数说明:
* node 插入的结点 // 对应《算法导论》中的node
*/
private void insert(RBTNode<T> node) {
int cmp;
RBTNode<T> y = null;
RBTNode<T> x = this.mRoot;
// 1. 将红黑树当作一颗二叉查找树,将节点添加到二叉查找树中。
while (x != null) {
y = x;
cmp = node.key.compareTo(x.key);
if (cmp < 0)
x = x.left;
else
x = x.right;
}
node.parent = y;
if (y!=null) {
cmp = node.key.compareTo(y.key);
if (cmp < 0)
y.left = node;
else
y.right = node;
} else {
this.mRoot = node;
}
// 2. 设置节点的颜色为红色
node.color = RED;
// 3. 将它重新修正为一颗二叉查找树
insertFixUp(node);
}
/*
* 新建结点(key),并将其插入到红黑树中
*
* 参数说明:
* key 插入结点的键值
*/
public void insert(T key) {
RBTNode<T> node=new RBTNode<T>(key,BLACK,null,null,null);
// 如果新建结点失败,则返回。
if (node != null)
insert(node);
}
这里就不对红黑树具体展开了,有兴趣大家可以百度自行学习相关知识,不然就脱离该文主题了
可以看到RBTree继承了Comparable没错,为啥呢?
首先咋们知道红黑树是属于二叉查找树的一种,而二叉查找树有一个特性就是:任意一个节点所包含的键值,大于等于左孩子的键值,小于等于右孩子的键值。
一看到涉及到元素比较了,那么就自然而然的想到compareTo()方法了,而只有将类强制转换为Comparable类型之后才能调用compareTo()方法,但是若你没有实现Comparable接口,那当然就不能强制准换了。
再看上面添加操作的代码,里面也有使用node.key.compareTo(x.key),自然就需要继承了Comparable。
不过话说Comparable接口也就只有compareTo()方法嘿嘿。
分析源码
ok,现在咋们知道为什么红黑树需要实现Comparable接口了,那咋们来看看HashMap1.8,它的红黑树是怎么一回事?
HashMap1.8之前也带大家分析过了,不清楚的小伙伴可以看看 hashCode()和hash算法的那些事儿 ,HashMap扫盲 , 浅谈HashMap线程安全问题 。
HashMap的putVal()方法里有添加到红黑树的操作: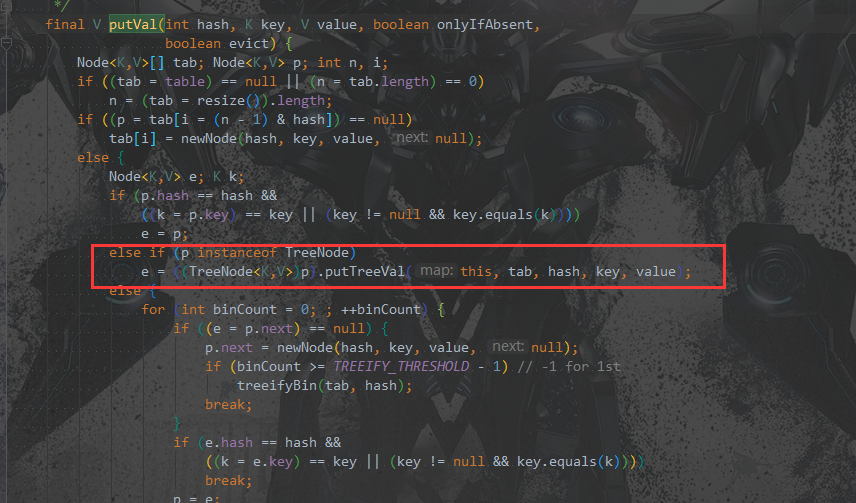
注意:HashMap内部自己实现了个红黑树TreeNode。
贴下TreeNode(部分,具体实现被缩起来了)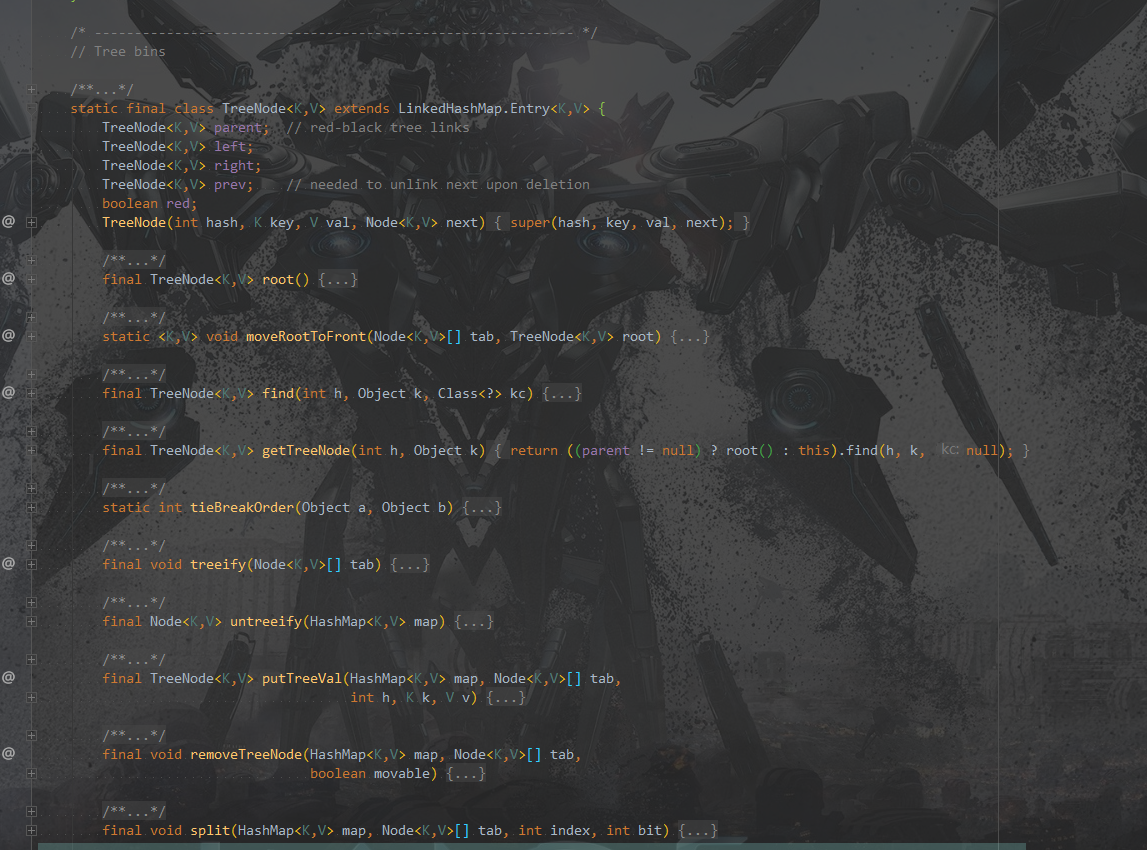
一个TreeNode代表红黑树的一个节点。
可以看到TreeNode继承了LinkedHashMap.Entry<K,V>而后者又继承了HashMap.Node<K,V>…绕来绕去的,最后又是HashMap的Node,总之TreeNode是红黑树的同时也是一个链表。
再看看它的putTreeVal方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
啥?看不懂?这些参数怎么那么多?都是干嘛的?不急不急,咋们看源码的时候,有时候不需要所有变量名都知道是干啥的,要学会找自己需要的。而且源码起名字都很规范的,就比如这个putTreeVal方法,你需要找的是什么?之前Java版红黑树的添加方法里面用到了比较方法compareTo是不是?那你就应该找现在这个putTreeVal方法有没有类似的比较方法呢??
咋们先扫一遍这个putTreeVal方法,咦!突然看到了两个不得了的东西:comparableClassFor和comparableClassFor方法!为啥是这两个呢?看名字就知道这两货肯定和比较(comparable)有关嘛,恭喜你,答对了!TreeNode就是根据这两个方法判断大小的。
咋们看看这两个方法到底是何方神圣:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45/**
* Returns x's Class if it is of the form "class C implements
* Comparable<C>", else null.
* 如果对象x的类是C,如果C实现了Comparable<C>接口,那么返回C,否则返回null
*/
static Class<?> comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // bypass checks 如果x是个字符串对象,返回String.class
return c;
/*
* 为什么x是个字符串就直接返回c了呢 ? 因为String 实现了 Comparable 接口
*/
// 如果 c 不是字符串类,获取c直接实现的接口(如果是泛型接口则附带泛型信息)
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) { // 遍历接口数组
// 如果当前接口t是个泛型接口
// 如果该泛型接口t的原始类型p 是 Comparable 接口
// 如果该Comparable接口p只定义了一个泛型参数
// 如果这一个泛型参数的类型就是c,那么返回c
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
// 上面for循环的目的就是为了看看x的class是否 implements Comparable<x的class>
}
}
return null; // 如果c并没有实现 Comparable<c> 那么返回空
}
/**
* Returns k.compareTo(x) if x matches kc (k's screened comparable
* class), else 0.
* 如果x所属的类是kc,返回k.compareTo(x)的比较结果
* 如果x为空,或者其所属的类不是kc,返回0
*/
({"rawtypes","unchecked"}) // for cast to Comparable
static int compareComparables(Class<?> kc, Object k, Object x) {
return (x == null || x.getClass() != kc ? 0 :
((Comparable)k).compareTo(x));
}
代码注释已经写得很清楚了,comparableClassFor方法判断这个key的类有没有实现Comparabledir = tieBreakOrder(k, pk);,这里dir值又被改了!所以tieBreakOrder方法也属于一个比较方法!
来看看tieBreakOrder方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/**
* Tie-breaking utility for ordering insertions when equal
* hashCodes and non-comparable. We don't require a total
* order, just a consistent insertion rule to maintain
* equivalence across rebalancings. Tie-breaking further than
* necessary simplifies testing a bit.
* 用这个方法来比较两个对象,返回值要么大于0,要么小于0,不会为0
* 也就是说这一步一定能确定要插入的节点要么是树的左节点,要么是右节点,不然就无法继续满足二叉树结构了
* 先比较两个对象的类名,类名是字符串对象,就按字符串的比较规则
* 如果两个对象是同一个类型,那么调用本地方法为两个对象生成hashCode值,再进行比较,hashCode相等的话返回-1
*/
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
很明显,tieBreakOrder方法就是最终的比价方法了,而且肯定会分出个胜负。
继续往下走到1
2
3
4if (dir <= 0)
xp.left = x;
else
xp.right = x;
根据dir确定是左节点还有右节点了,流程也就大体的结束了。
结论
HashMap自己实现了红黑树内部类TreeNode,TreeNode继承与LinkedHashMap.Entry<K,V>。红黑树实现comparable是为了调用它的compareTo方法,而HashMap自己实现了comparableClassFor、compareComparables、tieBreakOrder来进行Key的比较。
至此,这篇文章也结束了,最后想告诉大家的是多看看源码还是对自己帮助很大的,尤其是要看其注解。之前看到一段对话,感触颇深:
大家自行体悟吧。
希望大家可以从我找结论的过程中可以学到些东西。

