上期回顾
之前的一篇 剑指ConcurrentHashMap【基于JDK1.8】 给大家详细分析了一波JUC的ConcurrentHashMap,它在线程安全的基础上提供了更好的写并发能力。那么既然有map,是不是还有List呢?并发情况下应该用什么List嘞?接下来就是咋们的主角CopyOnWriteArrayList登场。
简介
首先咋们先看名字,比ArrayList多了个CopyOnWrite。CopyOnWrite啥意思?写时拷贝!OK,CopyOnWriteArrayList精髓你已经知道了,就是写时拷贝!很easy是把。
贴个比较官方的简介
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
先说说ArrayList的缺点
大家都知道ArrayList是属于线程不安全的一个集合,为什么不安全?咋们先看下它的添加操作源码1
2
3
4
5public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
很easy,里面有两步操作
- 判断列表的capacity容量是否足够,是否需要扩容
- 真正将元素放在列表的元素数组里面
ensureCapacityInternal()这个方法的详细代码我们可以暂时不看,它的作用就是判断如果将当前的新元素加到列表后面,列表的elementData数组的大小是否满足,如果size + 1的这个需求长度大于了elementData这个数组的长度,那么就要对这个数组进行扩容。
这里就出现了线程安全问题,注意,add操作实际上不是一个原子操作,是分两步执行的,先扩容,后赋值。
问题出现在elementData[size++] = e这里,它不是一个原子操作,可以分解为elementData[size] = e;和size++。当然,有经验的朋友可能还会说size++也不是原子操作,对,没错,++其实在字节码指令里面被分成了三步操作,不懂的朋友可以参考我之前写的 CAS机制是什么鬼?
看测试案例:
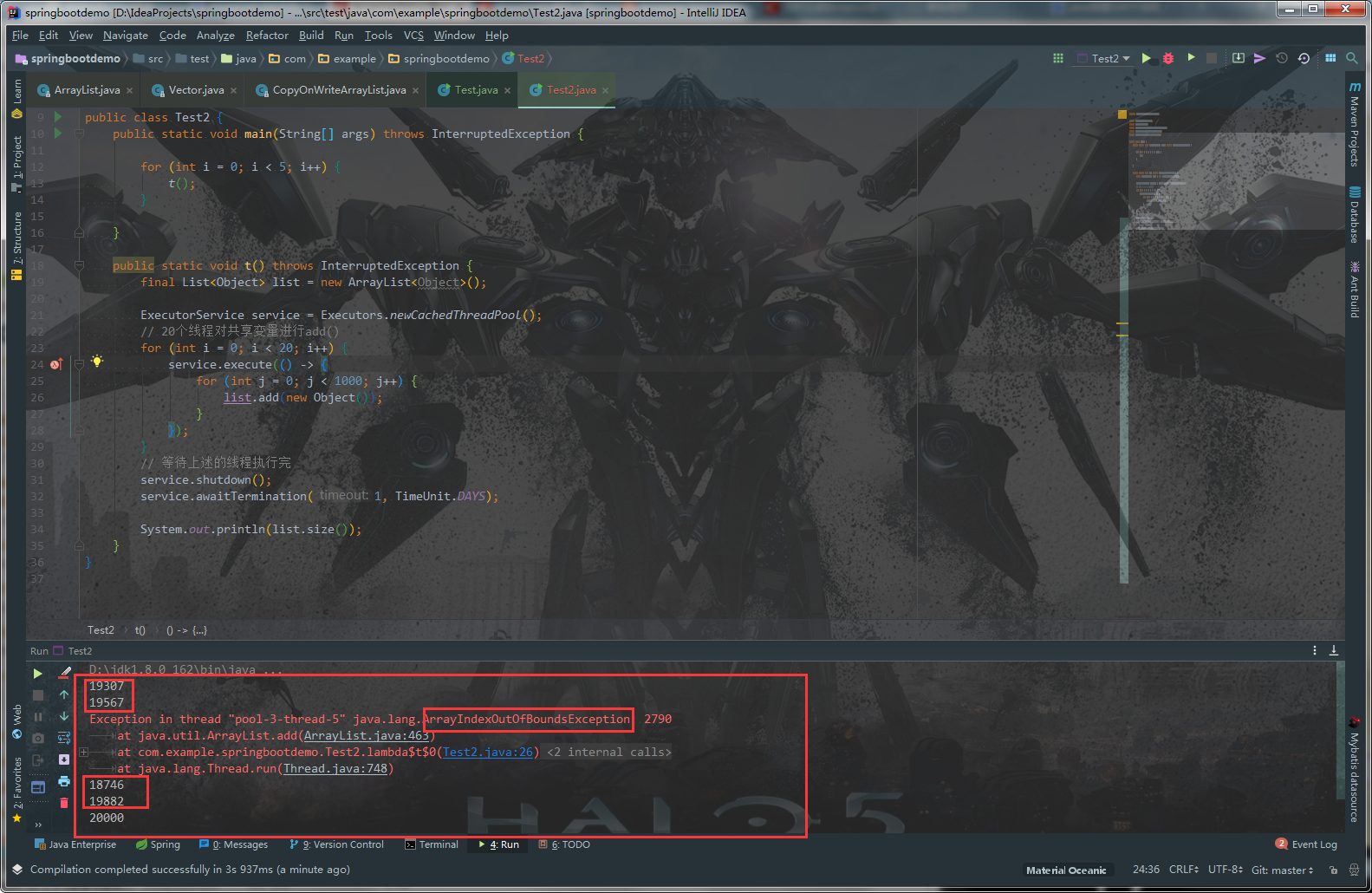
开了20个线程进行add()操作1000次,理论上每次size应该都是20000,但是出现很多不足20000的情况。
由此可见是ArrayList做add操作时候,会丢失一些数据,个别情况还会报java.lang.ArrayIndexOutOfBoundsException错!
值不足20000是典型的ArrayList多线程值覆盖问题。即AB线程同时进行add()方法,假设同时得到size为1,elementData[n]的值被设置了两次,第二个线程设置的值将前一个覆盖,第一个值丢失。
另一种情况是报错,主要是因为扩容引起的。假设一个场景:
list容量为10,当前的size为9。线程AB同时add一个元素,A执行完ensureCapacityInternal(size + 1)后,没达到扩容条件,此时容量还是为4,被挂起。B拿到CPU执行权,也执行了ensureCapacityInternal(size + 1),当然也不会进行扩容操作,接着执行elementData[size++] = e后,B的值添加成功,size变成了4!OK!这时候A拿到CPU了,执行elementData[size++] = e,因为这时size已经是4了,执行elementData[4]就肯定会报数组越界异常了啊!
OK,缺点说完,那多线程情况下咋整呢?
Vector和Collections.synchronizedList
我们知道 Vector是线程安全的容器,因为它大部分方法都是用synchronized关键字确保线程安全,比如add():1
2
3
4
5
6public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
包括使用Collections.synchronizedList(new ArrayList())来使ArrayList变成是线程安全,也和Vector实现方法差不多,比如add():1
2
3public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
只不过它不是加在方法的声明处,而是方法的内部。
Vector和Collections.synchronizedList可能会出现的问题
有朋友就说了,咋还有问题啊,这是闹啥子啊??别急,听我慢慢道来。
直接贴案例图
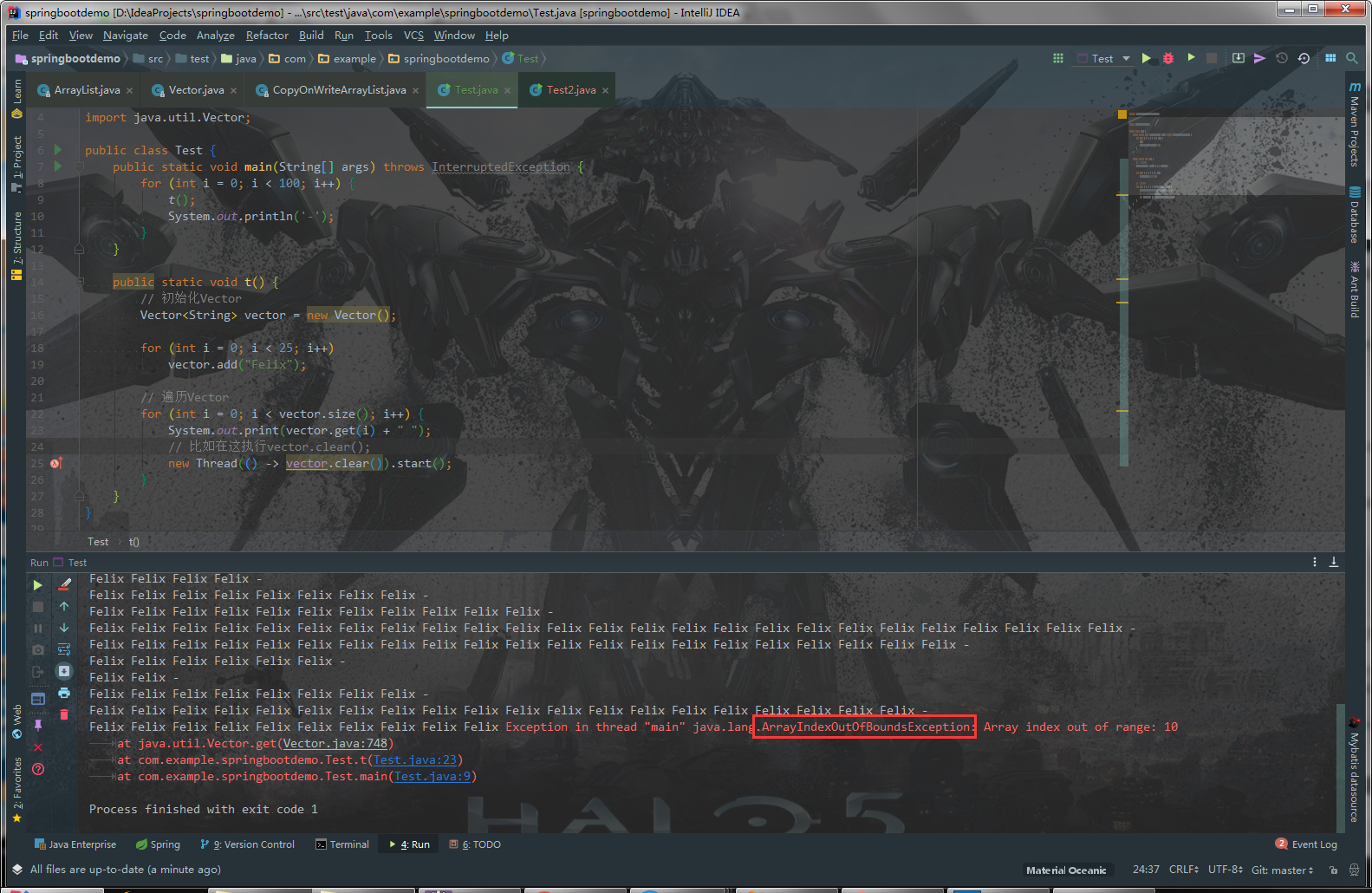
我们在遍历Vector的时候,有别的线程修改了Vector的长度,可能会报java.lang.ArrayIndexOutOfBoundsException错误。为什么呢?假设:A线程遍历Vector,发现Vector长度为25,这时候B线程进来了,吧Vector清空了,之后A继续执行vector.get(i)操作的时候,抛出异常。
怎么解决??
很简单,加锁!
1 | // 遍历Vector |
这样就不会有之前的问题了,但是你随便遍历个集合都要加个synchronized,性能方面肯定大打折扣的,这时候咋们的主角CopyOnWriteArrayList就出来了。
CopyOnWriteArrayList源码分析
看下add()方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public boolean add(E e) {
// 加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 得到原数组的长度和元素
Object[] elements = getArray();
int len = elements.length;
// 复制出一个新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 添加时,将新元素添加到新数组中
newElements[len] = e;
// 将volatile Object[] array 的指向替换成新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
通过代码我们可以知道:在添加的时候就上锁,并复制一个新数组,增加操作在新数组上完成,将array指向到新数组中,最后解锁。
再看看set()方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 得到原数组的旧值
Object[] elements = getArray();
E oldValue = get(elements, index);
// 判断新值和旧值是否相等
if (oldValue != element) {
// 复制新数组,新值在新数组中完成
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
// 将array引用指向新数组
setArray(newElements);
} else {
// Not quite a no-op; enssures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
和add()方法有异曲同工之妙
总结:
- 在修改时,复制出一个新数组,修改的操作在新数组中完成,最后将新数组交由array变量指向。
- 写加锁,读不加锁
对之前两个案例进行改进:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class Test2 {
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 5; i++) {
t();
}
}
public static void t() throws InterruptedException {
final List<Object> list = new CopyOnWriteArrayList<Object>();
ExecutorService service = Executors.newCachedThreadPool();
// 20个线程对共享变量进行add()
for (int i = 0; i < 20; i++) {
service.execute(() -> {
for (int j = 0; j < 1000; j++) {
list.add(new Object());
}
});
}
// 等待上述的线程执行完
service.shutdown();
service.awaitTermination(1, TimeUnit.DAYS);
System.out.println(list.size());
}
}
1 | public class Test { |
测试运行是没有问题的。
CopyOnWriteArrayList的缺点
啥?CopyOnWriteArrayList还有缺点?ArrayList不行换Vector,Vector不行换CopyOnWriteArrayList,现在CopyOnWriteArrayList咋又不行啦??没完没了了??这代码我不敲了!!!
哈哈,不急不急,稍安勿躁,且听我慢慢道来。
CopyOnWriteArrayList也不是万金油,固然它有许多优点,但是也有两个缺点。
- 内存占用问题
因为CopyOnWrite的写时拷贝机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在拷贝的时候只是拷贝容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,比如ConcurrentHashMap。 - 数据一致性问题
CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
注意事项
- 使用CopyOnWriteArrayList应该尽量在创建时指定合适的大小,减少扩容开销,避免写时CopyOnWriteArrayList扩容的开销。
- 尽量使用批量添加方法
addAll(),因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。

