前几篇文章hashCode()和hash算法的那些事儿 和 HashMap扫盲 详细介绍了HashMap的实现原理,还不熟悉的小伙伴可以去回顾下。
这篇文章主要介绍下HashMap线程安全方面的问题,为什么多线程情况下不安全?怎么避免线程安全问题?以及引出接下来我准备写关于ConcurrentHashMap的文章,达到过度效果吧。
多线程rehash的时候如何造成闭环链表
看下1.7resize()源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
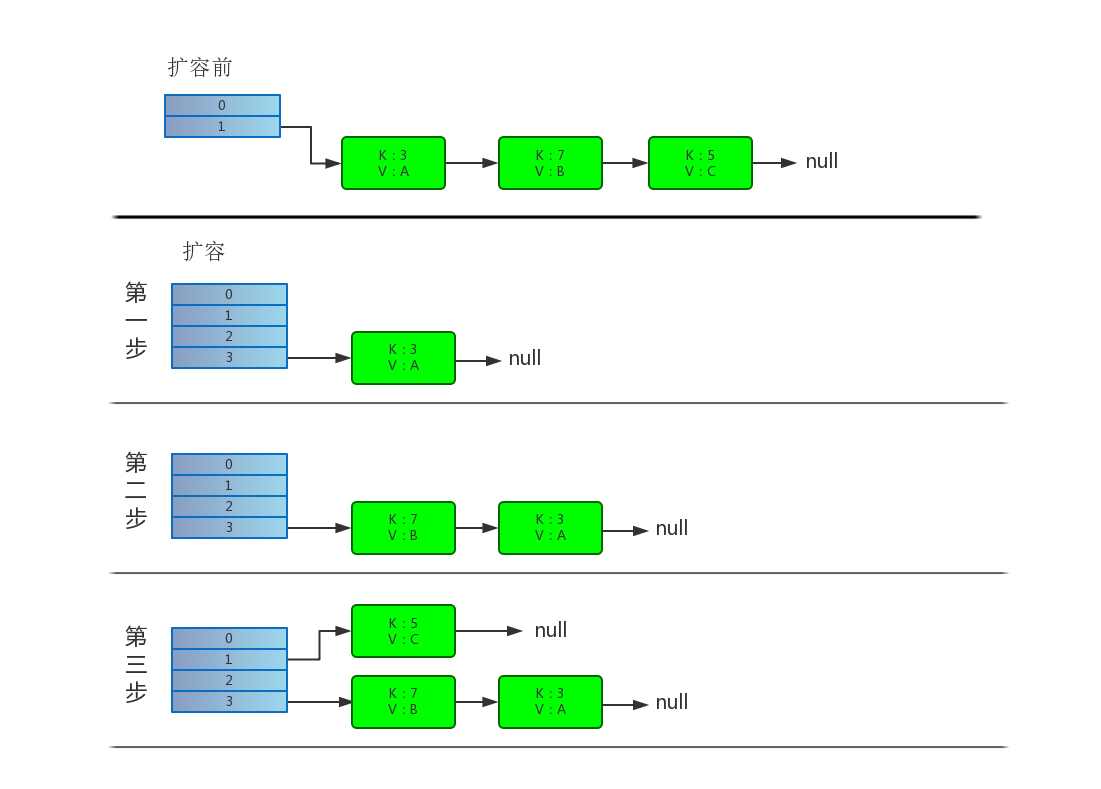
transfer()操作过程说下:
- for循环对原数组遍历
- while循环对链表上的每一个节点遍历,用 next 取得要转移那个元素的下一个,将 e 转移到新 Hash 表的头部,使用
头插法插入节点。
使用的是头插法,加入之前链表顺序为1-2-3,那么转以后就是3-2-1了,死锁问题就是因为1-2的同时2-1造成的,所以HashMap死锁问题就出现在transfer了。
单线程下 rehash 操作详细演示
多线程下 rehash 操作详细演示
抽取transfer关键代码:1
2
3
4
5
6while(null != e) {
Entry<K,V> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
}
解释下操作过程:
Entry<K,V> next = e.next,保存下一个结点e.next = newTable[i],e 要插入到链表的头部,所以要先用 e.next 指向新的 Hash 表第一个元素(为什么不加到新链表最后?因为复杂度是 O(N))newTable[i] = e,将新 Hash 表的头指针指向 ee = next,转移 e 的下一个结点
假设两个线程同时进行put操作,都进入了transfer()方法1
2
3
4
5
6while(null != e) {
Entry<K,V> next = e.next; //线程1执行到这里被调度挂起了
e.next = newTable[i];
newTable[i] = e;
e = next;
}
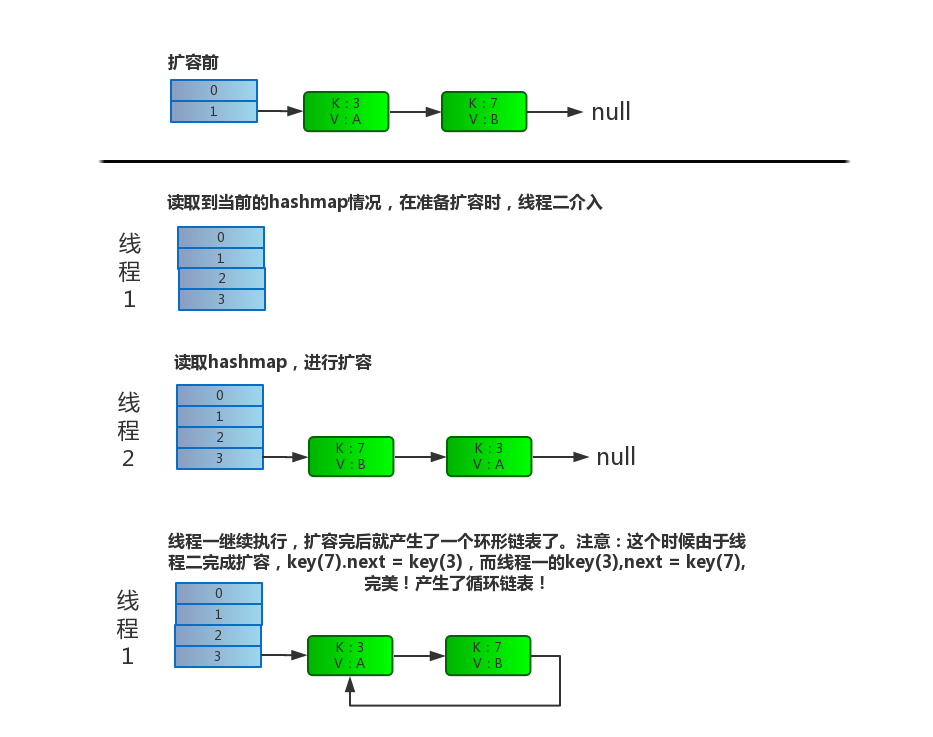
出现环形链表后,再进行get操作的话,就会死循环了(cpu100%),后果可想而知。。
所以jdk1.8之前多线程情况下使用HashMap会造成链表的循环。但是到了1.8,resize()方法被大规模的调整过,环形链表问题在1.8中已经不存在了。
改进之后的方法不再进行链表的逆转,而是保持原有链表的顺序,如果在多线程环境下,顶多会在链表后边多追加几个元素而已,不会出现环的情况。
数据丢失问题
这个问题是不管1.7还是1.8都存在的,相信在座的各位也都了解。也就是put的时候导致的多线程数据不一致。
图就不画了,直接说说大白话吧。
比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。。
以上就是HashMap线程不安全的原因了,所以在并发环境下不用HashMap,那么可以用什么呢?
介绍几个线程安全的Map
- Hashtable
- ConcurrentHashMap
- Synchronized Map
解决方案
Hashtable
Hashtable算是老朋友了吧,大家应该也挺熟悉他了。
Hashtable 源码中是使用 synchronized 来保证线程安全的,比如下面的 get 方法和 put 等方法:1
2
3
4
5
6
7public synchronized V put(K key, V value) { ... }
public synchronized V get(Object key) { ... }
public synchronized int size(Object key) { ... }
public synchronized boolean isEmpty() { ... }
public synchronized V remove(Object key) { ... }
public synchronized void putAll(Map<? extends K, ? extends V> t) { ... }
...
所以当一个线程访问 HashTable 的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。因此Hashtable效率很低,基本被废弃。。
SynchronizedMap
SynchronizedMap是Collectionis的内部类。1
Map m = Collections.synchronizedMap(new HashMap());
Collections.synchronizedMap()和Hashtable一样,实现上在调用map所有方法时,都对整个map进行同步。效率还是硬伤。
ConcurrentHashMap
ConcurrentHashMap和HashMap很像,底层依然由数组+链表+红黑树。但是为了做到并发,又增加了很多优化,相对于Hashtable,他并没有对整个hash表进行锁定,而是采用了分离锁(segment)的方式进行局部锁定,极大提升了效率。ConcurrentHashMap方面这里就不多说了,此篇文章主要是承上启下,我会单独写一篇或者几篇文章来对ConcurrentHashMap进行深度分析,敬请期待!

