上一篇文章 hashCode-和hash算法的那些事儿 详细讲解了hash算法,其中挖了几个小坑,在这篇来填坑。
HashMap的底层数组长度总是为2的整次幂?
首先咋们先创建一个HashMap1
Map map = new HashMap(16);
将会执行HashMap的一个有参构造:1
2
3public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
然后调用this(initialCapacity, DEFAULT_LOAD_FACTOR);,DEFAULT_LOAD_FACTOR默认为0.75f。如下:1
2
3
4
5
6
7
8
9
10
11
12public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
第一个if简单判断长度。
第二个判断的是initialCapacity如果大于MAXIMUM_CAPACITY的话,就等于MAXIMUM_CAPACITY,MAXIMUM_CAPACITY是HashMap指定的一个最大容量,值为1<<30,1左移30,就是1*2的30次方,值为1073741824。为什么是30次方呢?因为如果是31的话就是负数-2147483648了,1<<30是最接近int的最大值的。
第三个判断也简单不说了。
注意this.threshold = tableSizeFor(initialCapacity);这里调用了tableSizeFor方法
来看下tableSizeFor方法实现:1
2
3
4
5
6
7
8
9static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
新手可能看到这一脸懵逼,哎呀这啥啊,怎么那么多无符号右移运算,或运算??
别急,一步一步来。
假设咋们初始化大小为17,把值代入:
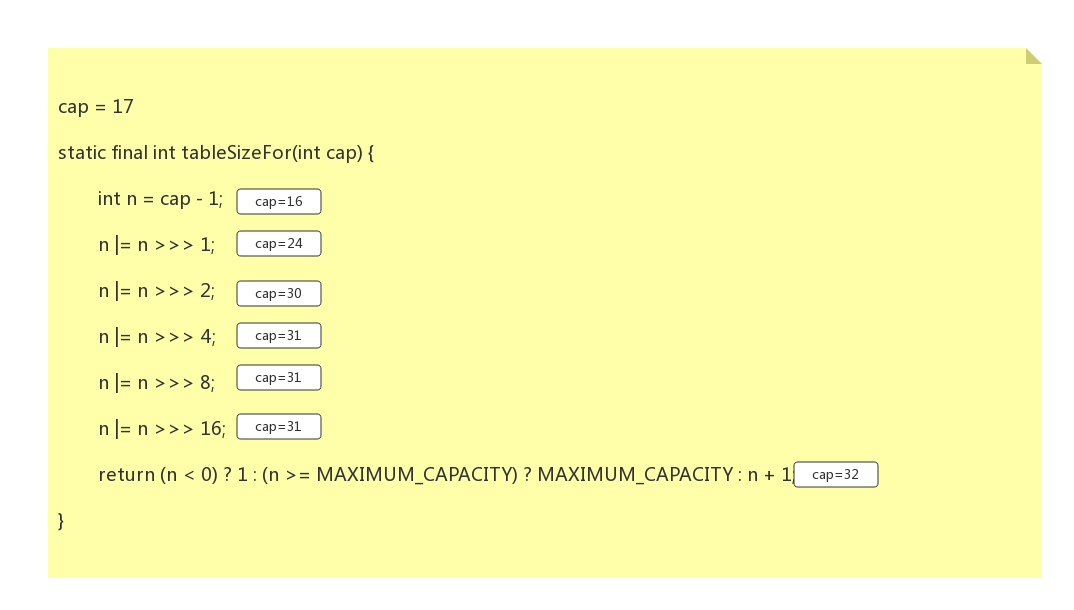
可以看到返回32
再测试其它几个数字吧1
2
3
4int[] arr = {1,12,16,17,23,33,43,54,67,344};
for (int i = 0; i < arr.length; i++) {
System.out.print(tableSizeFor(arr[i]) + " ");
}
结果:1
1 16 16 32 32 64 64 64 128 512
观察该结果,我们发现这些数字都是2的n次幂,并且,返回的结果还是离该整数最近的2次幂。比如cap=17,离它最近的2次幂是32;cap=43,离它最近的2次幂是64;cap=16,离它最近的2次幂是16,即本身。
所以,咋们初始化HashMap的时候,你给它指定的长度不管是奇数还是偶数,经过tableSizeFor方法后,都会重新赋值为离该整数最近的2次幂。
HashMap到底是什么时候初始化的?
当你在敲下代码1
Map map = new HashMap(16);
的时候,你以为这个map初始化了吗?贴下构造方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
很明显构造方法里面并没有对这个map初始化,即使你指的了长度为16,它也仅仅是将这个数字先进行tableSizeFor函数运算再保存!!
那么什么时候才会初始化呢?答案是添加操作。
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
可以看到第一个if判断,table为null的时候,调用resize()方法,去初始化table
看下resize:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42 final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; // table就是buckets数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// oldCap大于0,进行扩容,设置阈值与新的容量
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// oldCap = 0,oldThr大于0,那么就把阈值做为新容量以进行初始化
// 这种情况发生在用户调用了带有参数的构造函数(会对threshold进行初始化)
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// oldCap与oldThr都为0,这种情况发生在用户调用了无参构造函数
// 采用默认值进行初始化
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//创建
({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
...
}
return newTab;
}
看代码我们可以知道,当调用new HashMap(16)时,会走oldThr > 0这个分支;调用new HashMap()时,会走else分支,然后执行Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];完成初始化,返回newTab。
所以,HashMap初始化是在第一次put元素的时候进行的。
JDK1.8HashMap存储结构做了哪些优化?
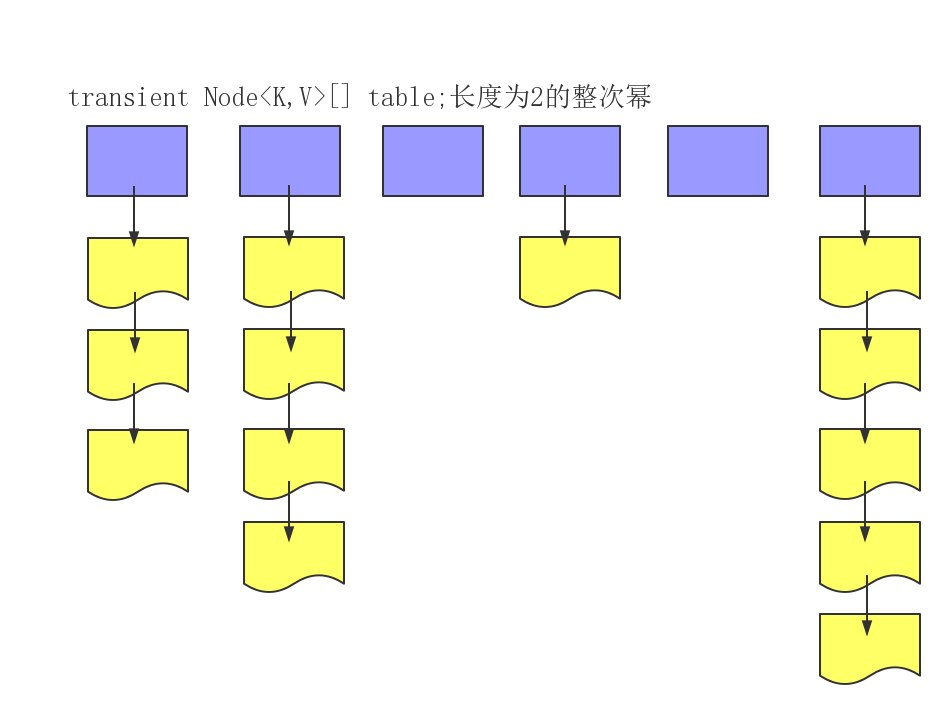
1.8之前
存储结构采用的是数组与链表相结合的方式,数组存储的是链表的链头,链接下一个节点。存储方式如下图所见。也即是哈希拉链法,该设计方式旨在解决哈希冲突(碰撞),哈希值相同时,存储于同一条链表。
1.8
引入了红黑树,当链表长度大于一定阈值时,将链表转换为红黑树,结构如下。

使用红黑树的原因主要是随着数据越来越多,hash冲突也越来越多,原先的链表也越来越长,查询也越来越慢,因此引入红黑树结构,红黑树能够以O(log2(N))的时间复杂度进行搜索、插入、删除操作,效率可以得到很大的提升。
查看默认阈值情况如下源码,默认树化的阈值为 8,而链表化的阈值为 6。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
JDK1.8HashMap添加操作优化
1.8之前:
1 | public V put(K key, V value) { |
操作过程:
- 根据key计算hash
- 根据hash计算下标
- 若该链头为空,则创建节点,插入该值作为链头。
- 若链头不为空,则遍历该链表,通过验证哈希值 与 key.equals(k) 相结合的验证方式寻找 key 值节点。并且,该结合方式也有助于减少验证的计算,因为哈希不相等必定键值不相等,相等才通过 equals 函数验证。
4.1 若找到该键值,则修改对应值。
4.2 否则,在链头插入该值节点。
1.8之后:put 函数的底层由 putVal 实现
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
操作过程:
- 数组是否为null,为null就就行
resize() - 判断该哈希值对应的下标地址是否为空,如果为空,则插入该值作为新节点。
- 判断该链头是否哈希值相等且键值相等,若是,则修改该节点的值。
- 否则,验证该节点是否为红黑树,若是,进行
putTreeVal操作插入到红黑树中。 - 若不是红黑树,即是链表,则与 JDK 1.8 之前插入方式相同(如上所述)。
扩容操作
HashMap的容量超过当前数组长度(DEFAULT_INITIAL_CAPACITY)加载因子(DEFAULT_LOAD_FACTOR),就会执行resize()算法。假设初始长度为16,加载因子默认为0.75,`160.75=12`,当HashMap容量超过12时,就会执行扩容操作。长度是原来的两倍(旧的长度左移一位),并且将原来的HashMap数组的节点转换到新的数组。
1 | final Node<K,V>[] resize() { |
了解了以上几个操作,再看下put()操作流程图回顾下:

