基于Python的词云生成类库,很好用,而且功能强大.博主个人比较推荐
安装库
1 | pip install wordcloud |
话不多说,直接上代码
实例
1 | # -*- coding: utf-8 -*- |
text文本是《阿里传》
font为字体路径
Wordcloud各参数含义
1 | font_path : string #字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf' |
背景图
效果图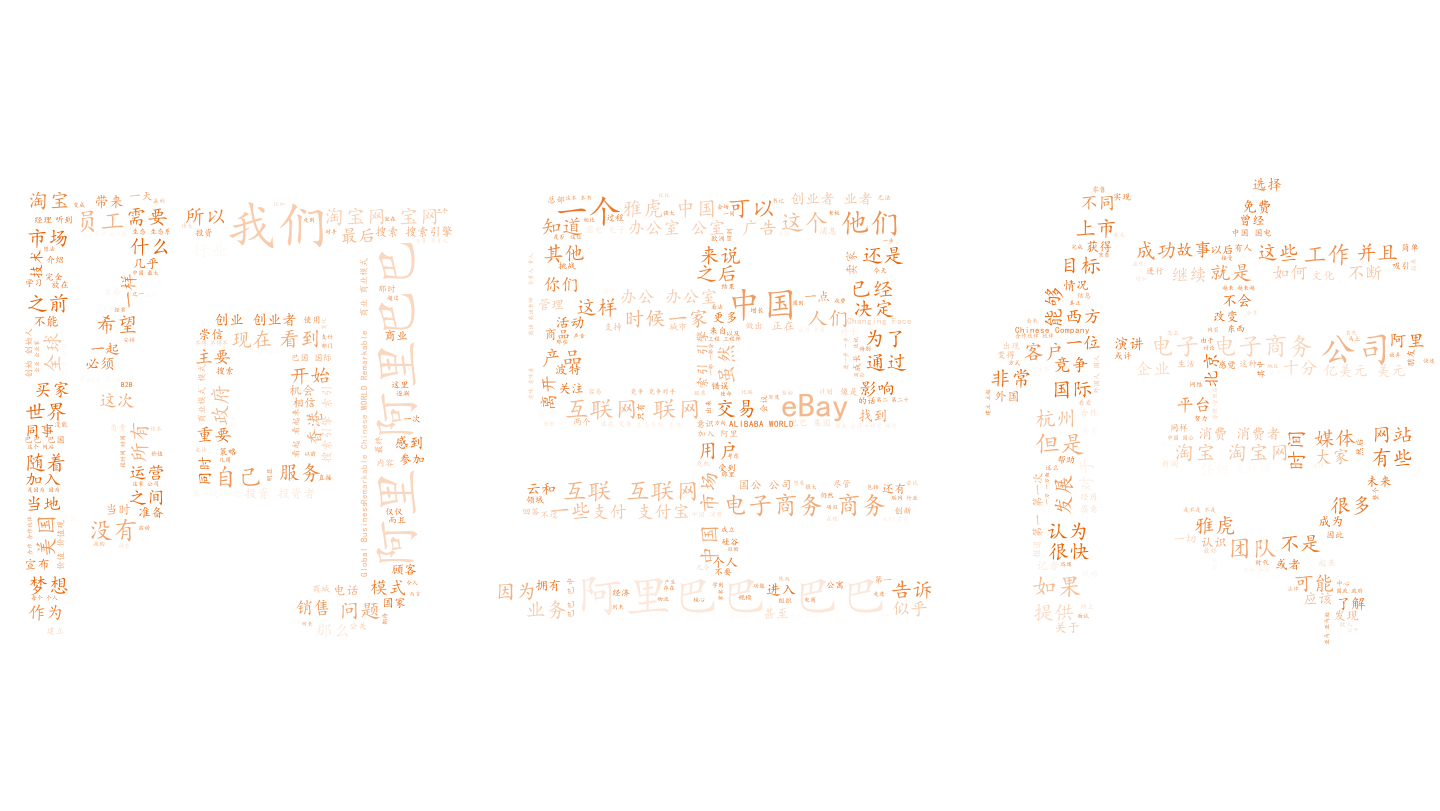
基于Python的词云生成类库,很好用,而且功能强大.博主个人比较推荐
1 | pip install wordcloud |
话不多说,直接上代码
1 | # -*- coding: utf-8 -*- |
text文本是《阿里传》
font为字体路径
1 | font_path : string #字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf' |
背景图
效果图

